
As part of our Linkerd 1.0 release last month, we snuck in something that a few people have picked up on—Linkerd’s service mesh API. With the 1.0 release happily out of the way, we thought we’d take a moment to explain what this API does and what it means for the future of Linkerd. We’ll also show off one of the upcoming features of this API—dynamic control over Linkerd’s per-service communications policy.
THE LINKERD SERVICE MESH
This morning at Gluecon, Buoyant CTO Oliver Gould delivered a keynote entitled The Service Mesh. In this keynote, he outlined the vision of the service mesh, as exemplified by Linkerd. While Linkerd is often added to systems built on Kubernetes for its ability to add resiliency, the full vision of the service mesh is much more than that. As William Morgan writes in his blog post, What’s a Service Mesh?:
The explicit goal of the service mesh is to move service communication out of the realm of the invisible, implied infrastructure, and into the role of a first-class member of the ecosystem—where it can be monitored, managed and controlled.
For Linkerd, this means that every aspect of its behavior should be not only instrumented and observable, but also *controllable* at runtime. And ideally, this mutability should take place, not via config file edits and hot reloading, but via a unified and well-designed runtime API.
This is, in short, the purpose of Linkerd’s service mesh API. To that end, we’ve introduced the io.l5d.mesh interpreter and a new gRPC API for Namerd. Together, these provide the ability to dynamically control routing policy, and form the core of Linkerd’s service mesh API. This is a first step towards the eventual goal of providing a unified, global model of control over every aspect of Linkerd’s behavior.
Linkerd 1.0 also introduced a new type of policy that *isn’t* yet exposed via the service mesh API—per-service communications policy. In this post, we’ll show how to configure this policy today, and we’ll describe the future work needed to add this control to Linkerd’s service mesh API.
This article is one of a series of articles about Linkerd, Kubernetes, and service meshes. Other installments in this series include:
- Top-line service metrics
- Pods are great, until they’re not
- Encrypting all the things
- Continuous deployment via traffic shifting
- Dogfood environments, ingress, and edge routing
- Staging microservices without the tears
- Distributed tracing made easy
- Linkerd as an ingress controller
- gRPC for fun and profit
- The Service Mesh API (this article)
- Egress
- Retry budgets, deadline propagation, and failing gracefully
- Autoscaling by top-line metrics
COMMUNICATIONS POLICY
Linkerd’s new per-service *communications policy* is an oft-requested feature. Communications policy encompasses many different aspects of how Linkerd proxies a request, including: how long should we wait for a service to process a request before timing out? What kinds of requests are safe to retry? Should we encrypt communication with TLS and which certificates should we use? And so on.
Let’s take a look at how this policy can be used today, with the example of two services that have wildly different latencies.
Starting from a fresh Kubernetes cluster, let’s deploy two services with different latencies. We can deploy the hello world microservice that we’re familiar with from the other posts in this series, with one small tweak: the hello service will be configured to add 500ms of artificial latency.
- name: service
image: buoyantio/helloworld:0.1.2
args:
- "-addr=:7777"
- "-text=Hello"
- "-target=world"
- "-latency=500ms"Deploy it to your Kubernetes cluster with this command:
kubectl apply -f https://raw.githubusercontent.com/BuoyantIO/linkerd-examples/master/k8s-daemonset/k8s/hello-world-latency.yml(Note that the examples in these blog posts assume Kubernetes is running in an environment like GKE, where external loadbalancer IPs are available, and no CNI plugins are being used. Slight modifications may be needed for other environments—see our Flavors of Kubernetes forum posting for how to handle environments like Minikube or CNI configurations with Calico/Weave.)
Our next step will be to deploy the Linkerd service mesh. We’d like to add a timeout so that we can abort (and potentially retry) requests that are taking too long, but we’re faced with a problem. The world service is fast, responding in less than 100ms, but the hello service is slow, taking more than 500ms to respond. If we set our timeout just above 100ms, requests to the world service will succeed, but requests to the hello service are guaranteed to timeout. On the other hand, if we set our timeout above 500ms then we’re giving the world service a much longer timeout than necessary, which may cause problems to *our* callers.
To give each service an appropriate timeout, we can use Linkerd 1.0’s new fine-grained per-service configuration to set a separate communications policy for each service:
service:
kind: io.l5d.static
configs:
- prefix: /svc/hello
totalTimeoutMs: 600ms
- prefix: /svc/world
totalTimeoutMs: 100msThis configuration establishes the following timeouts:
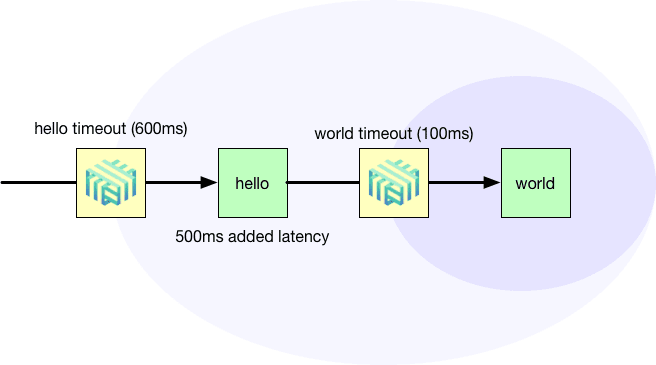
We can deploy the Linkerd service mesh with this configuration using this command:
kubectl apply -f https://raw.githubusercontent.com/BuoyantIO/linkerd-examples/master/k8s-daemonset/k8s/linkerd-latency.ymlOnce Kubernetes provisions an external LoadBalancer IP for Linkerd, we can test requests to both the hello and world services and make sure both are operating within their timeouts.
$ L5D_INGRESS_LB=$(kubectl get svc l5d -o jsonpath="{.status.loadBalancer.ingress[0].*}")
$ curl $L5D_INGRESS_LB:4140 -H "Host: hello"
Hello (10.196.1.242) world (10.196.1.243)!!
$ curl $L5D_INGRESS_LB:4140 -H "Host: world"
world (10.196.1.243)!!(Note that the first few requests will be slower because they must establish connections and may time out. Subsequent requests should be successful.)
We can also check that timeouts are being enforced by artificially increasing the latency of the hello and world services until they violate their timeouts. We’ll start by increasing the artificial latency of the hello service to 600ms. Given that the timeout for the hello service is 600ms, this leaves zero overhead for the hello service to do things like call the world service and any requests should therefore timeout:
$ curl "$L5D_INGRESS_LB:4140/setLatency?latency=600ms" -X POST -H "Host: hello"
ok
$ curl $L5D_INGRESS_LB:4140 -H "Host: hello"
exceeded 600.milliseconds to unspecified while waiting for a response for the request, including retries (if applicable). Remote Info: Not AvailableSimilarly, we can add 100ms of artificial latency to the world service which should cause all requests to the world service to violate the 100ms timeout.
$ curl "$L5D_INGRESS_LB:4140/setLatency?latency=100ms" -X POST -H "Host: world"
ok
$ curl $L5D_INGRESS_LB:4140 -H "Host: world"
exceeded 100.milliseconds to unspecified while waiting for a response for the request, including retries (if applicable). Remote Info: Not AvailableSuccess! We’ve set appropriate timeouts for each service, and demonstrated the expected behavior when these timeouts are (and are not) violated.
In this example, we’ve only been configuring timeouts, but, as you might expect, this same pattern can be used to configure any kind of per-service communications policy, including response classification or retry budgets.
LOOKING FORWARD
In this post, we’ve seen an example of using Linkerd’s new per-service communications policy to handle two services with wildly different expected latencies. The introduction of per-service communications policy solves some immediate use cases for Linkerd users. But what we’ve seen here is just the beginning of communications policy control in Linkerd—this policy was developed from the ground up in a way that it can be dynamically updatable, with the explicit goal of making it a part of the service mesh API.
In the coming months, we’ll add this communications policy to Linkerd’s service mesh API, alongside routing policy. Looking still further, other forms of policy—including rate limiting, request forking policy, and security policy—are all on the Linkerd roadmap, and will form more of Linkerd’s service mesh API. A consistent, uniform, well-designed service mesh API with comprehensive control over Linkerd’s runtime behavior is central to our vision of Linkerd as the service mesh for cloud native applications.
There’s a lot of very exciting work ahead of us and it won’t be possible without input and involvement from the amazing Linkerd community. Please comment on an issue, discuss your use case on Discourse, hit us up on Slack, or—best of all—submit a pull request!


