

The development of distributed systems is full of strange paradoxes. The reasoning we develop as engineers working on a single computer can break down in unexpected ways when applied to systems made of many computers. In this article, we’ll examine one such case—how the introduction of an additional network hop can actually decrease the end-to-end response time of a distributed system.
Speed matters. Studies have shown that the introduction of as little as 100ms of additional latency can have a marked impact on human behavior. Generally speaking, we’d expect the introduction of a new component in a request path to increase latency.
In this light, we’re often asked about the latency impact of adding Linkerd to a system. The simple answer is “network time, plus about 1ms” (our goal is <1ms p95 at 1000qps). The more complex answer is: in most situations, Linkerd actually reduces end-to-end latency of your system (and improves success rate).
How is this magic possible? In short, Linkerd’s latency-aware load balancing can rapidly detect when instances are slow and shift request traffic away from them. By combining this behavior with circuit breaking and retries, Linkerd can dramatically decrease end-to-end latency in a distributed system—despite being “yet another component”.
Let’s take a look at a dramatic example of this behavior with some poorly-behaved services.
Quick Start
First let’s boot up a test environment:
git clone https://github.com/linkerd/linkerd-examples.git
cd linkerd-examples/add-steps
docker-compose build && docker-compose up -d
open http://$(docker-machine ip default):3000 # or equivalent docker ip addressIf everything worked correctly, you should see this:
What’s going on here?
You have just booted up parallel test clusters, a Linkerd cluster, and a baseline cluster:
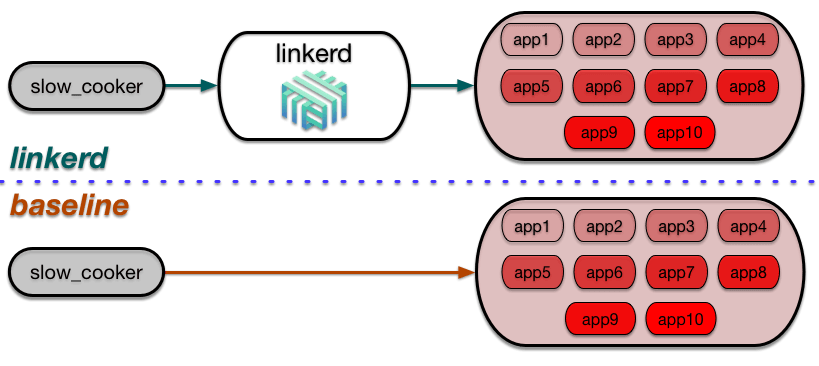
We are using our load tester, slow_cooker, to generate traffic. Each cluster consists of ten identical Go servers that serve a simple http endpoint. Instance response times vary between 0 and 2 seconds. The slowest instances also return an error response for a certain percentage of requests.
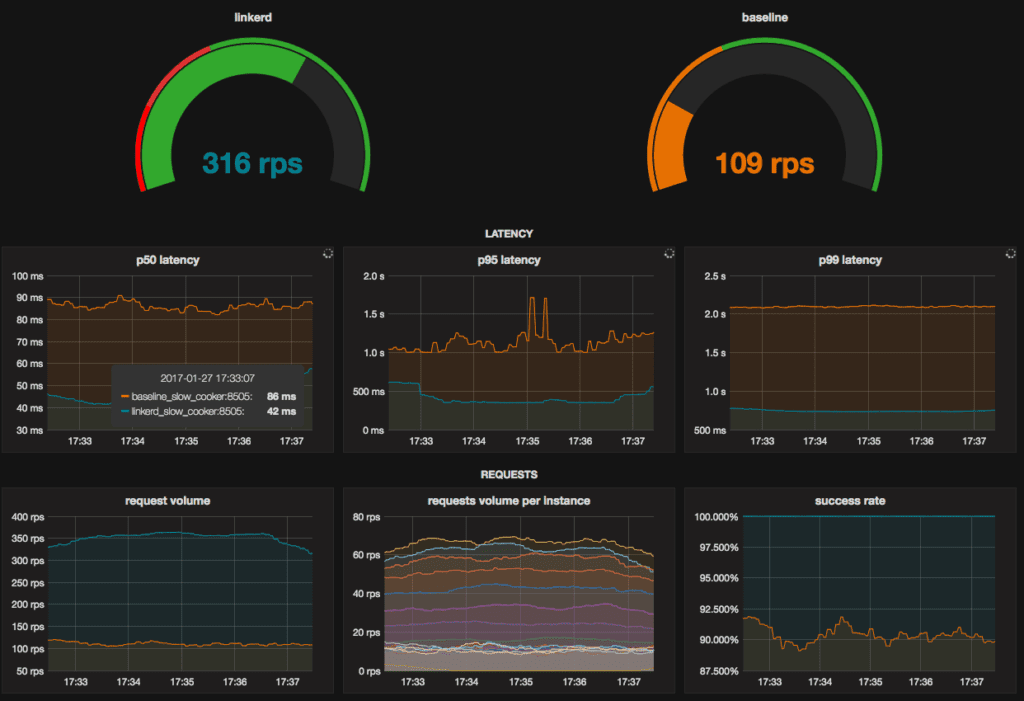
Comparing these two clusters, we observe the following results:
| linkerd | baseline | |
|---|---|---|
| p50 latency | 42ms | 86ms |
| p95 latency | 604ms | 1739ms |
| p99 latency | 734ms | 2100ms |
| requests per second | 316rps | 109rps |
| success rate | 100% | 88.08% |
Note that p50 latency is more than twice as fast with Linkerd. p99 latency is 2.8x faster with Linkerd. Linkerd’s latency-aware load balancer is favoring the faster instances while the baseline cluster’s latency is severely degraded due to the slower instances. Success rate is 100% with Linkerd vs. 88.08% without, thanks to Linkerd’s automatic retry behavior.
All of these metrics have improved despite adding an extra network hop via Linkerd. It’s clear that round robin does not handle degraded hosts well. Host degradation like this is extremely common in the real world for many reasons, including failing hardware, network congestion, and noisy neighbors. These issues get even more common as you scale up.
Linkerd Tuning
To achieve these results, we tuned Linkerd to favor fast and healthy instances. Here is the relevant snippet from our Linkerd config:
responseClassifier:
kind: io.l5d.retryableRead5XX
client:
loadBalancer:
kind: ewma
failureAccrual:
kind: io.l5d.successRate
successRate: 0.9
requests: 20
backoff:
kind: constant
ms: 10000In the responseClassifier section, note the use of io.l5d.retryableRead5XX. We have configured Linkerd to retry 500s. This enables Linkerd to achieve 100% success rate even when some instances are failing. Of course, retrying a failing request adds latency for that request, but this is often a good tradeoff to make, since the alternative is a failed request.
In the loadBalancer section, note the use of EWMA. This algorithm computes an exponentially-weighted moving average over the latency of each instance, where recent latency performance is upweighted heavily. In our testing , thisload-balancing algorithm responds rapidly to changes in instance latency, allowing it to perform well when latency is inconsistent.
In the failureAccrual section, note the use of io.l5d.successRate. This is also computes an exponentially-weighted moving average, this time based on the success rate of each instance. In our testing, this failure accrual algorithm performs well when success rate is inconsistent.
For more information on configuration options available in Linkerd, have a look at our Configuration Reference.
Conclusion
In this example, we’ve seen how Linkerd can improve system throughput in the presence of failing and slow components, even though Linkerd itself adds a small amount of latency to each request. In our experience operating large-scale systems, this test environment demonstrates the types of performance issues and incidents that we have seen in production. A single request from the outside can hit 10s or even 100s of services, each having 10s or 100s of instances, any of which may be slow or down. Setting up Linkerd as your service mesh can help ensure latency stays low and success rate stays high in the face of inconsistent performance and partial failure in your distributed systems.
If you have any questions about this post, Linkerd, or distributed systems in general, feel free to stop by our Linkerd community Slack, post a topic on Linkerd discourse, or contact us directly.
Acknowledgements
Thanks to Alex Leong and Kevin Lingerfelt for feedback on earlier drafts of this post.
[1] A Note About Round Robin
It was surprisingly difficult to find a DNS client that would correctly round robin IP addresses. You may have noticed that this demo uses a slow_cooker built on golang 1.8rc2. This was required because golang 1.7 does not do round robin correctly. We also found that curl, ping, and anything relying on glibc’s getaddrinfo employ a sort function based on rfc6724. This results in a preference for certain IP addresses, or in some cases a single ip address.


