

One of the inevitabilities of moving to a microservices architecture is that you’ll start to encounter *partial failures*—failures of one or more instances of a service. These partial failures can quickly escalate to full-blown production outages. In this post, we’ll show how circuit breaking can be used to mitigate this type of failure, and we’ll give some example circuit breaking strategies and show how they affect success rate.
In previous posts, we’ve addressed the crucial role of load balancing in scaling microservice applications. Given a service with many instances, requests to that service must be balanced over all of the instances. This balancing can be done at the connection level, e.g. with systems like kubeproxy (Kubernetes) or Minuteman (DC/OS); or it can be done at the request level, with systems like haproxy or with Linkerd, our service mesh for cloud native applications.
Request-level load balancing requires protocol-specific code. A system that balances HTTP traffic cannot be used to balance requests to, say, memcache, without adding memcache support. However, request balancing also allows for powerful techniques that can dramatically improve system resilience. For example, Linkerd does latency-aware load balancing, which allows it to reduce end-to-end latency by automatically shifting traffic away from slow instances. This can make a tremendous difference in overall application performance.
Hence, request-level load balancing protects our requests from the degradation that is caused by a slow backend instance. But what happens when an instance isn’t slow, but is failing requests? If a given instance is returning errors, but doing so rapidly, latency-aware load balancing might actually send it more traffic! These failing requests may later be retried against other instances, but this is clearly not a good situation.
Circuit breaking
Enter circuit breaking. As the name suggests, circuit breaking will shut off traffic to an individual instance if it fails requests too frequently. For example, if an instance starts failing 50% of requests, circuit breaking could further prevent requests from hitting this instance in the first place. By removing failing instances from the load balancer pool, circuit breaking can not only improve overall success rate, it can reduce latency by reducing the rate of retries.
Even better, circuit breaking can provide powerful benefits to failure recovery. Since partial failures are often tied to high request load, a tripped circuit breaker can give failing instances a chance to recover by reducing the overall amount of traffic that they are receiving. In the event of a full-service outage, circuit breaking can even help protect against resource depletion, a situation in which multiple callers are stuck waiting on responses from a failing service. Resource depletion is a common cause of cascading failures within distributed systems.
Implementing circuit breaking in your own system can be tricky, however, especially if there are multiple frameworks and languages in play. When should the breaker be tripped? When should it be reset? Should we make the failure determination by number of failures, by a rate, or by a ratio? How do we know when an instance is healthy if it’s not receiving traffic? These details, and the complex interplay between circuit breaking, load balancing, and retry strategies, can be quite difficult to get right in practice.
Fortunately, Linkerd makes available the battle-hardened, incredibly well-tested circuit breaking code that’s built into Finagle. Like many of Linkerd’s reliability features, this code is used at scale every day at companies like Twitter, Pinterest, and Soundcloud. And as of the Linkerd 0.8.5 release, we are happy to report that Linkerd’s circuit breaking is now configurable by changing the way Linkerd does “failure accrual”—the measure of instance health that determines whether a circuit breaker is tripped. This means that you can tune Linkerd’s circuit breaking for the specific failure patterns you want to prevent.
In the rest of this post, we’ll explore the impact of various failure accrual settings on success rate, and we’ll demonstrate a specific case where choosing the right circuit breaking strategy immediately improves site success rate in the presence of partial failures.
Setup
To test various circuit breaking settings, we’ve setup a failure-accrual demo project in the linkerd-examples repo. The project’s README contains a lot of helpful information about how the demo is constructed, but suffice to say you can run it locally by cloning the repo and spinning up all of the services using docker-compose. Like so:
git clone https://github.com/linkerd/linkerd-examples.git
cd linkerd-examples/failure-accrual
docker-compose build && docker-compose up -dThe demo runs Linkerd configured with multiple different routers, each using a different failure accrual configuration, as well as a Grafana dashboard to compare router performance. To view the dashboard, go to port 3000 on your docker host. It will look like this:
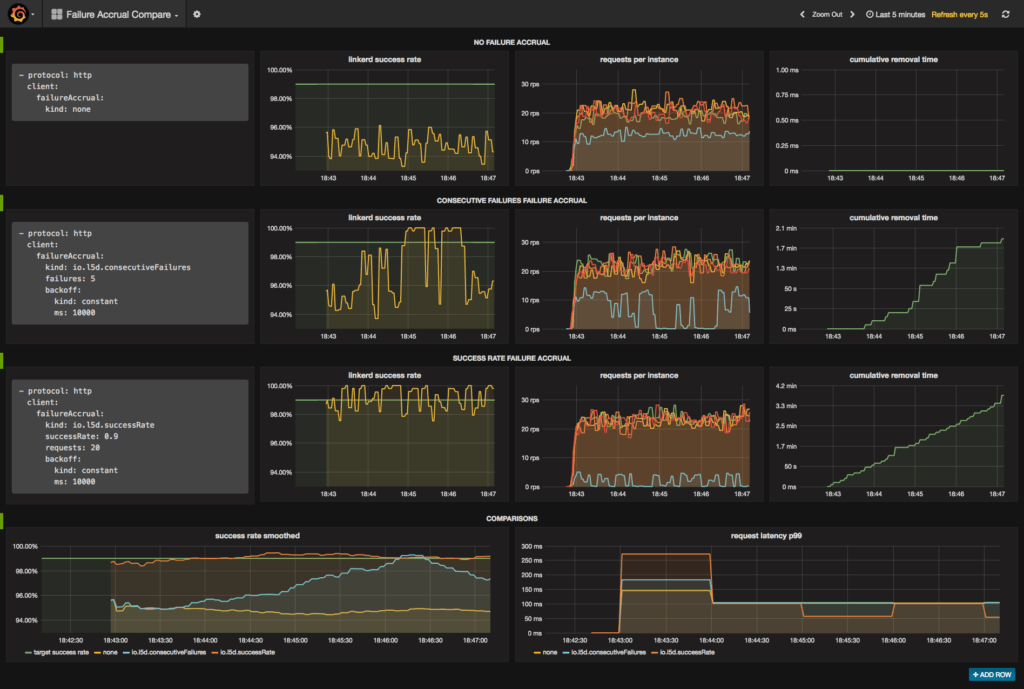
Armed with this dashboard, we’re now ready to start our comparison of different circuit breaking configurations.
Circuit breaking configurations
Linkerd’s failure accrual policy consists of two parts, as follows:
- Failure threshold: This is the part of the policy that Linkerd uses to determine whether or not it should remove an instance from the load balancer pool. Once an instance has been removed, Linkerd will periodically send it test requests (called probes). If the probe succeeds, the instance will be added back into the load balancer pool. There are multiple different types of thresholds available, and those are covered in the rest of this section.
- Backoff interval: This is the part of the policy that Linkerd uses to determine how often it should probe removed instances to determine if they have recovered. There are two types of backoff intervals: constant and jittered. A constant backoff instructs Linkerd to wait a fixed amount of time between each probe. A jittered backoff is configured with a minimum and maximum wait time. Linkerd will send its first probe after the minimum wait time, but if the probe fails, it will increase its wait time before sending the next probe, until the maximum wait time is reached.
Linkerd’s default policy uses a threshold of 5 consecutive failures, with a jittered backoff interval between 5 seconds and 5 minutes.
In the experiments below, we will vary the type of failure threshold used in each configuration. All configurations use the same constant backoff interval for the sake of comparison. We will also disable retries to better show the impact of changing failure accrual policy. In practice, it is likely that you want to enable retries.
NO CIRCUIT BREAKING
Let’s start by looking at the router that’s configured to disable circuit breaking altogether, with the following configuration:
routers:
- protocol: http
client:
failureAccrual:
kind: noneAs you would expect, under this configuration, Linkerd *never* removes unhealthy instances from the load balancer pool. In our demo setup, where one of the 5 backend instances has a 60% success rate, this yields the following success rate and distribution of requests across backend instances:
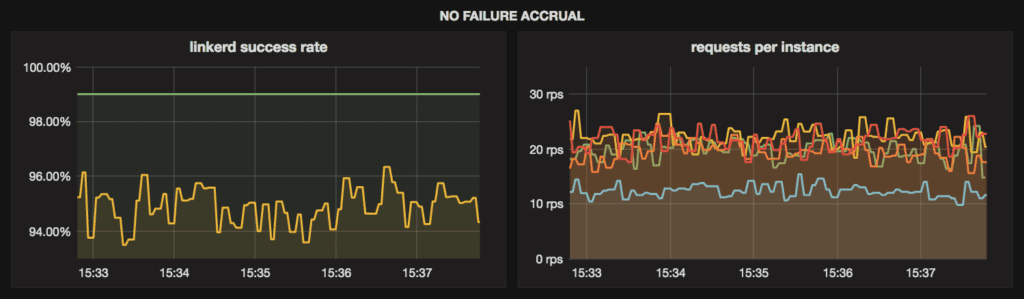
You can see that the failing instance is also serving fewer requests, since our demo setup adds latency to failing requests and Linkerd is load balancing requests based on observed queue sizes. It’s worth noting that the overall success rate would be even worse with a naive load balancing algorithm, such as round robin, where all instances receive the same number of requests, regardless of performance. In that case we’d expect to see overall success rate hovering around 92%, with the unhealthy backend failing 2 out of every 25 requests to the cluster.
CONSECUTIVE FAILURES
Next, let’s look at the router with Linkerd’s default circuit breaking configuration, which has a failure threshold of 5 consecutive failures:
routers:
- protocol: http
client:
failureAccrual:
kind: io.l5d.consecutiveFailures
failures: 5
backoff:
kind: constant
ms: 10000This configuration tells Linkerd to remove any instance that has failed 5 requests in a row. In our demo setup it yields the following success rate and distribution of requests across backend instances:
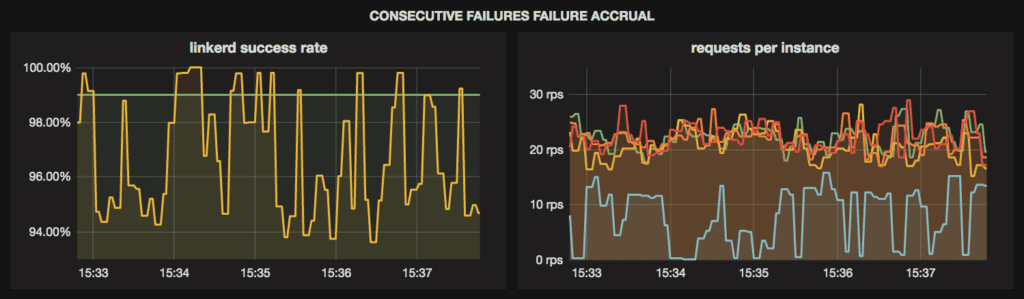
This configuration, with Linkerd’s default circuit breaking, shows a marked improvement in overall success rate compared to the previous configuration with no circuit breaking—from around 95% up to 97%. But it’s not perfect. At a 60% success rate for our one failing instance, there’s a very low probability that the unhealthy instance emits 5 consecutive failures and trips the circuit breaker. Thus, the failing instance remains in the load balancer pool for large portions of the run, as illustrated in the requests per instance graph above. Removing this instance from the pool more quickly would improve the overall success rate.
SUCCESS RATE
While the default configuration above is clearly an improvement, we can further improve the effectiveness of our failure threshold since we know the approximate success rate and volume of requests to the failing backend. In the final configuration, we use a failure threshold based on a target success rate over a bounded number of requests, with the following configuration:
- protocol: http
client:
failureAccrual:
kind: io.l5d.successRate
successRate: 0.9
requests: 20
backoff:
kind: constant
ms: 10000This configuration tells Linkerd to remove any instance that has a success rate below 90%, computed over its 20 most recently completed requests. In our demo setup it yields the following success rate and distribution of requests across backend instances:
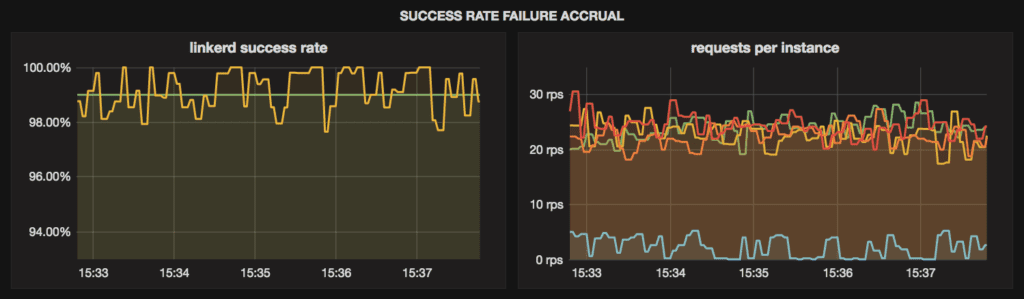
This improves our success rate from 97% in the previous configuration to approximately 99%. You can also see that, in this configuration, the unhealthy instance reaches the configured failure threshold much more quickly than in the previous configuration, which results in it being removed from the load balancer pool much more rapidly.
Discussion
We have shown that picking the right circuit breaking settings can have a dramatic impact on overall success rate. Let’s put all three success rates side-by-side, using a 90-second moving average to eliminate the spikes that come from adding and removing instances in quick succession:
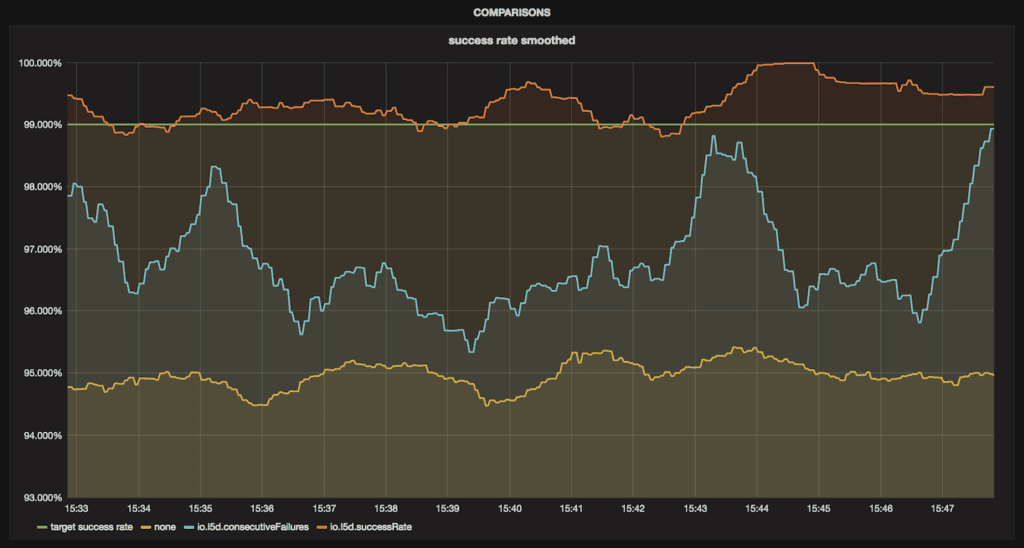
As you can see, the windowed success-rate-based circuit breaking yielded the highest success rate, around 99%, while the configuration without circuit breaking was around a 95% success rate—a tremendous difference. Circuit breaking based on consecutive failures was in the middle, with a success rate of around 97% over the window measured.
Of course, it’s important to recognize the tradeoffs that come with different failure accrual policies. Setting a failure threshold that is too low, and thus more likely to deem instances to be unhealthy faster, will improve success rate under certain conditions, but also runs the risk of shrinking the pool to an unacceptably small size. Conversely, setting a failure accrual threshold that is too high will result in fewer spurious removals, but it will also allow unhealthy instances to stay in the pool longer than they should.
The two types of policies, success rate and consecutive failures, are aimed at different types of failure scenarios. The consecutive failures policy (which is really just a special case of the success rate policy with the success rate threshold set to 0%) is useful to quickly detect when a backend instance goes into a state of complete failure, and can be used with a small window, as we did above. By contrast, the success-rate-based policy is better for detecting instances that are only partly degraded, but would typically require a longer window size in order to avoid accidentally triggering the breaker.
Conclusion
Circuit breaking is a powerful tool that can improve the resilience of your microservice applications in the face of partial failure. In Linkerd, it’s one of several such tools, alongside load balancing, response classification, and retries.
We’ve demonstrated how a little thought in circuit breaking strategy can go a long way toward improving the overall performance of your application. If you’re interested in trying this on your own systems with Linkerd, be sure to check out the full failure accrual API documentation for more configuration options. As always, you can reach us in the Linkerd Slack if you run into any issues.


