

Staging new code before exposing it to production traffic is a critical part of building reliable, low-downtime software. Unfortunately, with microservices, the addition of each new service increases the complexity of the staging process, as the dependency graph between services grows quadratically with the number of services. In this article, we’ll show you how one of linkerd’s most powerful features, per-request routing, allows you to neatly sidestep this problem.
This is one article in a series of articles about linkerd, Kubernetes, and service meshes. Other installments in this series include:
- Top-line service metrics
- Pods are great, until they’re not
- Encrypting all the things
- Continuous deployment via traffic shifting
- Dogfood environments, ingress, and edge routing
- Staging microservices without the tears (this article)
- Distributed tracing made easy
- Linkerd as an ingress controller
- gRPC for fun and profit
- The Service Mesh API
- Egress
- Retry budgets, deadline propagation, and failing gracefully
- Autoscaling by top-line metrics
For a video presentation of the concepts discussed in this article, see Alex Leong’s meetup talk, Microservice Staging without the Tears.
Linkerd is a service mesh for cloud-native applications. It acts as a transparent request proxy that adds a layer of resilience to applications by wrapping cross-service calls with features like latency-aware load balancing, retry budgets, deadlines, and circuit breaking.
In addition to improving application resilience, linkerd also provides a powerful routing language that can alter how request traffic flows between services at runtime. In this post, we’ll demonstrate linkerd’s ability to do this routing, not just globally, but on a per-request basis. We’ll show how this *per-request routing* can be used to create ad-hoc staging environments that allow us to test new code in the context of the production application, without actually exposing the new code to production traffic. Finally, we’ll show how (in contrast to staging with a dedicated staging environment) ad-hoc staging requires neither coordination with other teams, nor the costly process of keeping multiple deployment environments in sync.
Why stage?
Why is staging so important? In modern software development, code goes through a rigorous set of practices designed to assess correctness: code review, unit tests, integration tests, etc. Having passed these hurdles, we move to assessing behaviour: how fast is the new code? How does it behave under load? How does it interact with runtime dependencies, including other services?
These are the questions that a staging environment can answer. The fundamental principle of staging is that the closer to the production environment, the more realistic staging will be. Thus, while mocks and stub implementations make sense for tests, for staging, we ideally want actual running services. The best staging environment is one in which the surrounding environment is exactly the same as it will be in production.
Why is staging hard for microservices?
When your application consists of many services, the interaction between these services becomes a critical component of end-to-end application behaviour. In fact, the more that the application is disaggregated into services, the more that the runtime behaviour of the application is determined not just by the services themselves, but by the interactions between them.
Unfortunately, increasing the number of services doesn’t just increase the importance of proper staging, it also increases the difficulty of doing this properly. Let’s take a look at a couple common ways of staging, and why they suffer in multi-service environments.
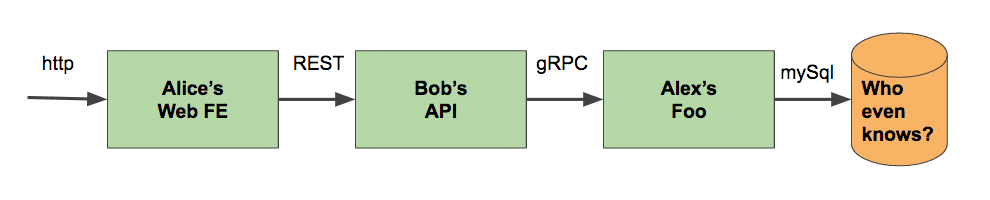
A frequent choice for staging is the shared staging cluster, wherein your staged service is deployed into a dedicated staging environment alongside other staged services. The problem with this approach is that there is no isolation. If, as in the diagram below, Alex deploys his Foo service and sees weird behaviour, it’s difficult to determine the source—it could be due to the staging deploys of Alex, Alice, or Bob, or simply the mock data in the database. Keeping the staging environment in sync with production can be very difficult, especially as the number of services, teams, and releases all start to increase.
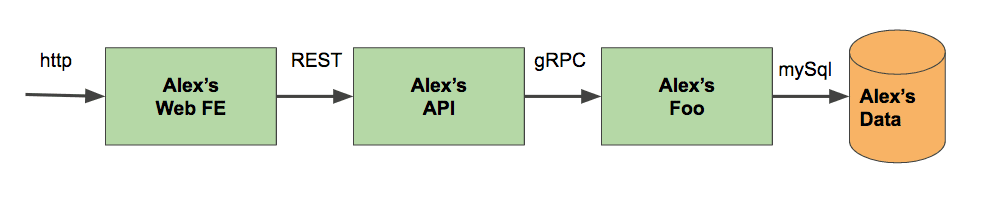
An alternative to the shared environment that addresses the lack of isolation is the “personal” or per-developer, staging cluster. In this model, every developer can spin up a staging cluster on demand. To keep our staging effective, staging a service requires staging its upstream and downstream dependencies as well. (For example, in the diagram below, Alex would need to deploy Web FE and API in order to ensure the changes he made to his Foo service are correctly reflected there.) Unfortunately, maintaining the ability to deploy arbitrary subsets of the application topology on demand also becomes very complex, especially as the application topology becomes larger, and as services have independent deployment models.
Finally, there is the (sadly prevalent!) option of simply deploying fresh code into production and rolling it back when flaws are discovered. Of course, this is rather risky, and may not be an option for applications that handle, e.g., financial transactions. There are many other ways you could obtain a staging environment, but in this article, we’ll describe a straightforward, tear-free approach.
A better path
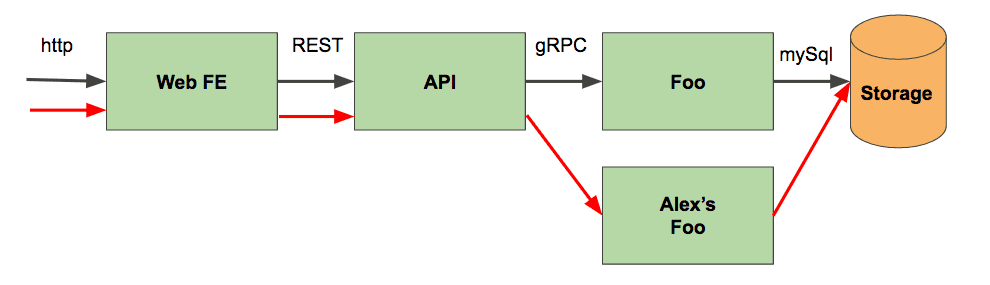
Fortunately, with linkerd, we can do staging without incurring the costs detailed above, by creating ad-hoc staging environments. In fact, one of the prime motivations for the routing layer in Finagle, the library underlying linkerd, was solving this very problem at Twitter! Let’s consider again the goal of staging Alex’s Foo service. What if, rather than deploying to a separate environment, we could simply substitute Foo-staging in place of Foo-production, for a specific request? That would give us the ability to stage Foo safely, against the production environment, without requiring any deployment other than that of Foo-staging itself. This is the essence of ad-hoc staging environments. The burden on the developer is now greatly eased: Alex must simply stage his new code, set a header on ingress requests, and voila!
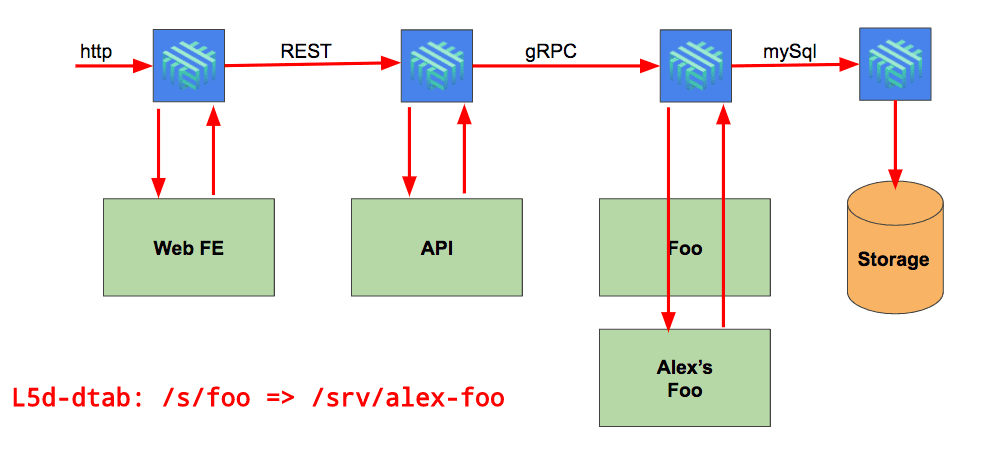
Happily, linkerd’s per-request routing allow us to do just this. With linkerd proxying traffic, we can set a routing “override” for a particular request using the l5d-dtabheader. This header allows you to set routing rules (called, in Finagle parlance, “Dtabs”) for that request. For example, the dtab rule /s/foo => /srv/alex-foo might override the production routing rule for Foo. Attaching this change to a single request would allow us to reach Alex’s Foo service, but only for that request. Linkerd propagates this rule, so any usage of Alex’s Foo service anywhere in the application topology, for the lifetime of that request, will be properly handled.
Trying this at home
Keen readers of our [Service Mesh for Kubernetes][part-i] series will note that we’ve already seen an example of this in [our dogfood blog post][part-v]. We deployed a world-v2 service, and we were able to send individual dogfood requests through this service via a simple header containing a routing override. Now, we can use this same mechanism for something else: setting up an ad hoc staging environment.
Let’s deploy two versions of a service and use linkerd’s routing capabilities to test our new service before using it in production. We’ll deploy our hello and world-v1services as our running prod services, and then we’ll create an ad-hoc staging environment to stage and test a new version of world, world-v2.
STEP 1: DEPLOY LINKERD AND OUR HELLO-WORLD SERVICES
We’ll use the hello world service from the previous blog posts. This consists of a hello service that calls a world service. These apps rely on the nodeName supplied by the Kubernetes downward API to find Linkerd. To check if your cluster supports nodeName, you can run this test job:
kubectl apply -f https://raw.githubusercontent.com/linkerd/linkerd-examples/master/k8s-daemonset/k8s/node-name-test.ymlAnd then looks at its logs:
kubectl logs node-name-testIf you see an ip, great! Go ahead and deploy the hello world app using:
kubectl apply -f https://raw.githubusercontent.com/linkerd/linkerd-examples/master/k8s-daemonset/k8s/hello-world.ymlIf instead you see a “server can’t find …” error, deploy the hello-world legacy version that relies on hostIP instead of nodeName:
kubectl apply -f https://raw.githubusercontent.com/linkerd/linkerd-examples/master/k8s-daemonset/k8s/hello-world-legacy.ymlLet’s deploy our prod environment (linkerd, and the hello and world services):
kubectl apply -f https://raw.githubusercontent.com/linkerd/linkerd-examples/master/k8s-daemonset/k8s/linkerd-ingress.ymlLet’s also deploy linkerd and the service we want to stage, world-v2, which will return the word “earth” rather than “world”.
kubectl apply -f https://raw.githubusercontent.com/linkerd/linkerd-examples/master/k8s-daemonset/k8s/linkerd-ingress.yml
kubectl apply -f https://raw.githubusercontent.com/linkerd/linkerd-examples/master/k8s-daemonset/k8s/world-v2.ymlSTEP 2: USE PER REQUEST OVERRIDES IN OUR AD-HOC STAGING ENVIRONMENT
So now that we have a running world-v2, let’s test it by running a request through our production topology, except that instead of hitting world-v1, we’ll hit world-v2. First, let’s run an unmodified request through our default topology (you may have to wait for l5d’s external IP to appear):
$ INGRESS_LB=$(kubectl get svc l5d -o jsonpath="{.status.loadBalancer.ingress[0].*}")
$ curl -H "Host: www.hello.world" $INGRESS_LB
Hello (10.196.2.232) world (10.196.2.233)!!Or if external load balancer support is unavailable for the cluster, use hostIP:
$ INGRESS_LB=$(kubectl get po -l app=l5d -o jsonpath="{.items[0].status.hostIP}"):$(kubectl get svc l5d -o 'jsonpath={.spec.ports[0].nodePort}')
$ curl -H "Host: www.hello.world" $INGRESS_LB
Hello (10.196.2.232) world (10.196.2.233)!!As we expect, this returns Hello (......) World (.....) from our production topology. Now, how do we get to the staging environment? All we have to do is pass the following dtab override and requests through the prod topology will go to world-v2! A dtab override is another dtab entry that we pass using headers in the request. Since later dtab rules are applied first, this rule will replace (override) our current “/host/world => /srv/world-v1” rule with a rule to send requests with /host/world to /srv/world-v2 instead.
$ curl -H "Host: www.hello.world" -H "l5d-dtab: /host/world => /srv/world-v2;" $INGRESS_LB
Hello (10.196.2.232) earth (10.196.2.234)!!We now see “earth” instead of “world”! The request is successfully served from the world-v2 service wired up to our existing production topology, with no code changes or additional deploys. Success! Staging is now fun and easy.
Dtabs and routing in linkerd are well documented. During development, you can also make use of linkerd’s “dtab playground” at http://$INGRESS_LB:9990/delegator. By going to the “outgoing” router and testing a request name like /http/1.1/GET/world, you can see linkerd’s routing policy in action.
In practice
In practice, there are some caveats to using this approach. First, the issue of writes to production databases must be addressed. The same dtab override mechanism can be used to send any writes to a staging database, or, with some application-level intelligence, to /dev/null. It is recommended that these rules are not created by hand so as to avoid expensive mistakes with production data!
Secondly, you application needs to forward linkerd’s context headers for this to work.
Lastly, it’s important to ensure that the l5d-dtab header is not settable from the outside world! In our post about [setting up a dogfood environment in Kubernetes][part-v], we gave an example nginx configuration for ingress that would strip unknown headers from the outside world—good practice for a variety of reasons.
Conclusion
We’ve demonstrated how to create ad-hoc staging environments with linkerd by setting per-request routing rules. With this approach, we can stage services in the context of production environment, without modifying existing code, provisioning extra resources for our staging environment (other than for the staging instance itself), or maintaining parallel environments for production and staging. For microservices with complex application topologies, this approach can provide an easy, low-cost way to staging services before pushing to production.
Note: there are a myriad of ways to deploy Kubernetes and different environments support different features. Learn more about deployment differences here.
For more about running linkerd in Kubernetes, or if you have any issues configuring ingress in your setup, feel free to stop by our linkerd community Slack, ask a question on Discourse, or contact us directly!
[part-i]: https://deploy-preview-1532--linkerdio.netlify.app/2016/10/04/a-service-mesh-for-kubernetes-part-i-top-line-service-metrics/ [part-ii]: https://deploy-preview-1532--linkerdio.netlify.app/2016/10/14/a-service-mesh-for-kubernetes-part-ii-pods-are-great-until-theyre-not/ [part-iii]: https://deploy-preview-1532--linkerdio.netlify.app/2016/10/24/a-service-mesh-for-kubernetes-part-iii-encrypting-all-the-things/ [part-iv]: https://deploy-preview-1532--linkerdio.netlify.app/2016/11/04/a-service-mesh-for-kubernetes-part-iv-continuous-deployment-via-traffic-shifting/ [part-v]: https://deploy-preview-1532--linkerdio.netlify.app/2016/11/18/a-service-mesh-for-kubernetes-part-v-dogfood-environments-ingress-and-edge-routing/ [part-vi]: https://deploy-preview-1532--linkerdio.netlify.app/2017/01/07/a-service-mesh-for-kubernetes-part-vi-staging-microservices-without-the-tears/ [part-vii]: https://deploy-preview-1532--linkerdio.netlify.app/2017/03/14/a-service-mesh-for-kubernetes-part-vii-distributed-tracing-made-easy/ [part-viii]: https://deploy-preview-1532--linkerdio.netlify.app/2017/04/06/a-service-mesh-for-kubernetes-part-viii-linkerd-as-an-ingress-controller/ [part-ix]: https://deploy-preview-1532--linkerdio.netlify.app/2017/04/19/a-service-mesh-for-kubernetes-part-ix-grpc-for-fun-and-profit/ [part-x]: https://deploy-preview-1532--linkerdio.netlify.app/2017/05/24/a-service-mesh-for-kubernetes-part-x-the-service-mesh-api/ [part-xi]: https://deploy-preview-1532--linkerdio.netlify.app/2017/06/20/a-service-mesh-for-kubernetes-part-xi-egress/


