
In our recent post about linkerd on Kubernetes, [A Service Mesh for Kubernetes, Part I: Top-line Service Metrics][part-i], observant readers noticed that linkerd was installed using DaemonSets rather than as a sidecar process. In this post, we’ll explain why (and how!) we do this.
Note: This is one article in a series of articles about linkerd, Kubernetes, and service meshes. Other installments in this series include:
- Top-line service metrics
- Pods are great, until they’re not (this article)
- Encrypting all the things
- Continuous deployment via traffic shifting
- Dogfood environments, ingress, and edge routing
- Staging microservices without the tears
- Distributed tracing made easy
- Linkerd as an ingress controller
- gRPC for fun and profit
- The Service Mesh API
- Egress
- Retry budgets, deadline propagation, and failing gracefully
- Autoscaling by top-line metrics
As a service mesh, linkerd is designed to be run alongside application code, managing and monitoring inter-service communication, including performing service discovery, retries, load-balancing, and protocol upgrades.
At a first glance, this sounds like a perfect fit for a sidecar deployment in Kubernetes. After all, one of Kubernetes’s defining characteristics is its pod model. Deploying as a sidecar is conceptually simple, has clear failure semantics, and we’ve spent a lot of time [optimizing linkerd for this use case][small-memory].
However, the sidecar model also has a downside: deploying per pod means that resource costs scale per pod. If your services are lightweight and you run many instances, like Monzo (who built an entire bank on top of linkerd and Kubernetes), then the cost of using sidecars can be quite high.
We can reduce this resource cost by deploying linkerd per host rather than per pod. This allows resource consumption to scale per host, which is typically a significantly slower-growing metric than pod count. And, happily, Kubernetes provides DaemonSets for this very purpose.
Unfortunately, for linkerd, deploying per host is a bit more complicated than just using DaemonSets. Read on for how we solve the service mesh problem with per-host deployments in Kubernetes.
A service mesh for Kubernetes
One of the defining characteristics of a service mesh is its ability to decouple application communication from transport communication. For example, if services A and B speak HTTP, the service mesh may convert that to HTTPS across the wire, without the application being aware. The service mesh may also be doing connection pooling, admission control, or other transport-layer features, also in a way that’s transparent to the application.
In order to fully accomplish this, linkerd must be on the sending side and the receiving side of each request, proxying to and from local instances. E.g. for HTTP to HTTPS upgrades, linkerd must be able to both initiate and terminate TLS. In a DaemonSet world, a request path through linkerd looks like the diagram below:
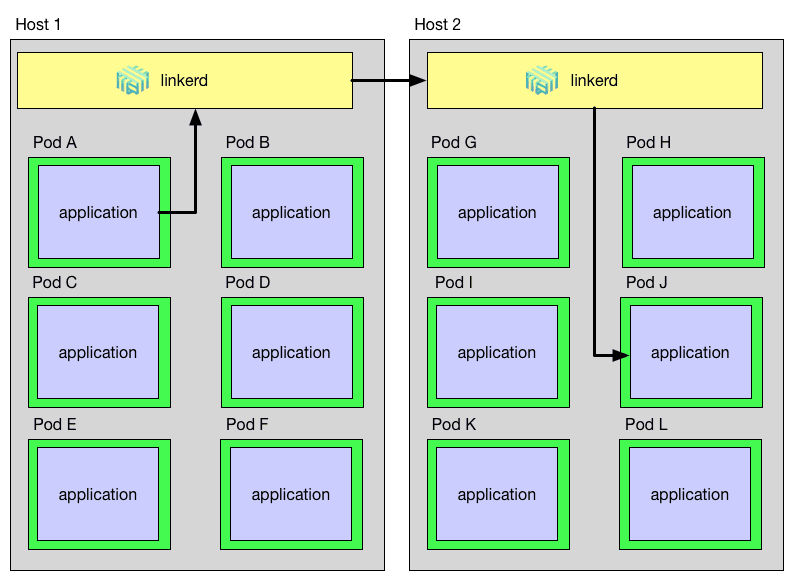
As you can see, a request that starts in Pod A on Host 1 and is destined for Pod J on Host 2 must go through Pod A’s *host-local* linkerd instance, then to Host 2’s linkerd instance, and finally to Pod J. This path introduces three problems that linkerd must address:
- How does an application identify its *host-local* linkerd?
- How does linkerd route an outgoing request to the destination’s linkerd?
- How does linkerd route an incoming request to the destination application?
What follows are the technical details on how we solve these three problems. If you just want to get linkerd working with Kubernetes DaemonSets, see the [previous blog post][part-i]!
HOW DOES AN APPLICATION IDENTIFY ITS HOST-LOCAL LINKERD?
Since DaemonSets use a Kubernetes hostPort, we know that linkerd is running on a fixed port on the host’s IP. Thus, in order to send a request to the linkerd process on the same machine that it’s running on, we need to determine the IP address of its host.
In Kubernetes 1.4 and later, this information is directly available through the Downward API. Here is an except from hello-world.yml that shows how the node name can be passed into the application:
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: http_proxy
value: $(NODE_NAME):4140
args:
- '-addr=:7777'
- '-text=Hello'
- '-target=world'(Note that this example sets the http_proxy environment variable to direct all HTTP calls through the *host-local* linkerd instance. While this approach works with most HTTP applications, non-HTTP applications will need to do something different.)
In Kubernetes releases prior to 1.4, this information is still available, but in a less direct way. We provide a simple script that queries the Kubernetes API to get the host IP; the output of this script can be consumed by the application, or used to build an http_proxy environment variable as in the example above.
Here is an excerpt from hello-world-legacy.yml that shows how the host IP can be passed into the application:
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: NS
valueFrom:
fieldRef:
fieldPath: metadata.namespace
command:
- '/bin/sh'
- '-c'
- 'http_proxy=`hostIP.sh`:4140 helloworld -addr=:7777 -text=Hello -target=world'Note that the hostIP.sh script requires that the pod’s name and namespace be set as environment variables in the pod.
HOW DOES LINKERD ROUTE AN OUTGOING REQUEST TO THE DESTINATION’S LINKERD?
In our service mesh deployment, outgoing requests should not be sent directly to the destination application, but instead should be sent to the linkerd running on that application’s host. To do this, we can take advantage of powerful new feature introduced in linkerd 0.8.0 called transformers, which can do arbitrary post-processing on the destination addresses that linkerd routes to. In this case, we can use the DaemonSet transformer to automatically replace destination addresses with the address of a DaemonSet pod running on the destination’s host. For example, this outgoing router linkerd config sends all requests to the incoming port of the linkerd running on the same host as the destination app:
routers:
- protocol: http
label: outgoing
interpreter:
kind: default
transformers:
- kind: io.l5d.k8s.daemonset
namespace: default
port: incoming
service: l5d
...HOW DOES LINKERD ROUTE AN INCOMING REQUEST TO THE DESTINATION APPLICATION?
When a request finally arrives at the destination pod’s linkerd instance, it must be correctly routed to the pod itself. To do this we use the localnode transformer to limit routing to only pods running on the current host. Example linkerd config:
routers:
- protocol: http
label: incoming
interpreter:
kind: default
transformers:
- kind: io.l5d.k8s.localnode
...Conclusion
Deploying linkerd as a Kubernetes DaemonSet gives us the best of both worlds—it allows us to accomplish the full set of goals of a service mesh (such as transparent TLS, protocol upgrades, latency-aware load balancing, etc), while scaling linkerd instances per host rather than per pod.
For a full, working example, see the [previous blog post][part-i], or download our example app. And for help with this configuration or anything else about linkerd, feel free to drop into our very active Slack or post a topic on linkerd discourse.
Acknowledgments
Special thanks to Oliver Beattie and Oleksandr Berezianskyi for their pioneering work on running linkerd as a DaemonSet, and to Joonas Bergius for contributing the Kubernetes 1.4 configuration.
[part-i]: https://deploy-preview-1532--linkerdio.netlify.app/2016/10/04/a-service-mesh-for-kubernetes-part-i-top-line-service-metrics/ [small-memory]: https://deploy-preview-1532--linkerdio.netlify.app/2016/06/17/small-memory-jvm-techniques-for-microservice-sidecars/


