
In this post, we’ll describe how we reduced the memory footprint of Linkerd, our JVM-based *service mesh* for cloud-native applications, by almost *80%*—from 500mb to 105mb—by tuning the JVM’s runtime parameters. We’ll describe why we went through this painful exercise, and the various things that did—and didn’t—help us get there.
Sidecars for Microservices
With the rise of microservices, a new deployment idiom is gaining in popularity: the “sidecar” (or “co-”) process. A sidecar sits alongside an application instance and provides additional functionality. Because it runs as a separate process, it’s decoupled from the implementation details of the application. Unlike a library, a sidecar doesn’t require the application to be written in a specific language or framework.
This decoupling is highly useful in microservices, because it’s a way for functionality to be shared across services, while still allowing individual services to be written in the language and framework most suited to the task at hand—as opposed to libraries, which constrain these choices. One of the strongest proponents of sidecars for this reason is Ben Christensen, Facebook (and formerly Netflix) engineer and author of Hystrix, who compares the heavy use of binary libraries in a microservices environment to “building a distributed monolith”.
So, the upside of the sidecar model is that it provides a consistent layer of functionality across all services without restricting design choices. The downside, of course, is that every instance of a sidecar consumes additional resources when deployed—memory, CPU, and disk.
Linkerd, our service mesh for cloud-native applications, is often deployed as a sidecar. Unfortunately for this deployment model (but fortunately for other reasons!), Linkerd is built on the JVM, which is not exactly known for its conservative resource profile—especially around memory. Additionally, the building blocks upon which Linkerd is built, Finagle and netty, have been extensively tuned and tested at production scale—but primarily in large-memory environments.
During our early work on Linkerd, we recommended 500mb as a healthy amount of memory for most workloads. However, while this was reasonable for per-host deployments, it became clear that it was too costly for most sidecar deployments.
The Challenge
To make Linkerd a more viable sidecar, we were faced with a challenge: could we take this JVM process, tuned and tested for large-memory, large-CPU environments, and squeeze it down into a resource profile that’s more palatable for microservices?
We started by trying to define the problem space. Since each Linkerd instance acts a stateless HTTP and RPC proxy, its tasks—request-level load balancing, routing, instrumentation, error and failure handling, and distributed tracing — don’t require disk. The resources that Linkerd consumes to drive network traffic are primarily CPU and memory.
Additionally, there are two metrics of Linkerd performance that we really care about: latency, especially tail latency, and throughput. In the JVM, as in most GC-based network systems, these things are all tightly related: CPU usage, memory footprint, latency, and throughput all either affect or are affected by one other.
On top of this, we imposed one inviolable constraint: the p99 latency of Linkerd must never break 1ms, and the p999 latency must never break 5ms. That is, for 99% of requests, time spent in Linkerd must be less than or equal to 1ms, and for another 0.9% of requests, time spent in Linkerd must be less than 5ms. Any configuration that exceeded these constraints would make Linkerd too slow, no matter how lightweight it was.
Since the JVM is a notorious memory hog, we knew that memory footprint would probably be the most difficult resource to optimize. To really push the envelope, we decided to target a 100mb memory footprint, as measured by resident set size (RSS). For those of you who live in the world of C programs land, this number may seem ridiculously large. For those of you who have have operated the JVM at scale, it’s laughably small.
Finally, we took advantage of one big feature of the sidecar deployment model: since we knew each Linkerd instance would be paired with an individual service instance, we didn’t have to support total service throughput—just that of a single instance. Thus, the throughput requirements could be very lax, by Linkerd standards.
From previous experiments, we knew that an individual Linkerd instance could saturate a 1GB Ethernet link with proxied traffic (roughly 40k HTTP requests per second (rps) proxied in and out). For a sidecar process, however, we could set the constraint much lower. We decided to target a measly 1,000 rps.
The Goal
The challenge was now in focus. Could we tune this JVM-based, Finagle- and netty-powered beast, born in a world of 32-core, 8-gig, bare metal machines, to operate in the confines of:
- a 100mb memory footprint (!), as measured by RSS;
- p99 of <= 1ms;
- p999 of <= 5ms; and
- “not excessive” CPU utilization;
… all while hitting 1,000 proxied HTTP rps?
Results
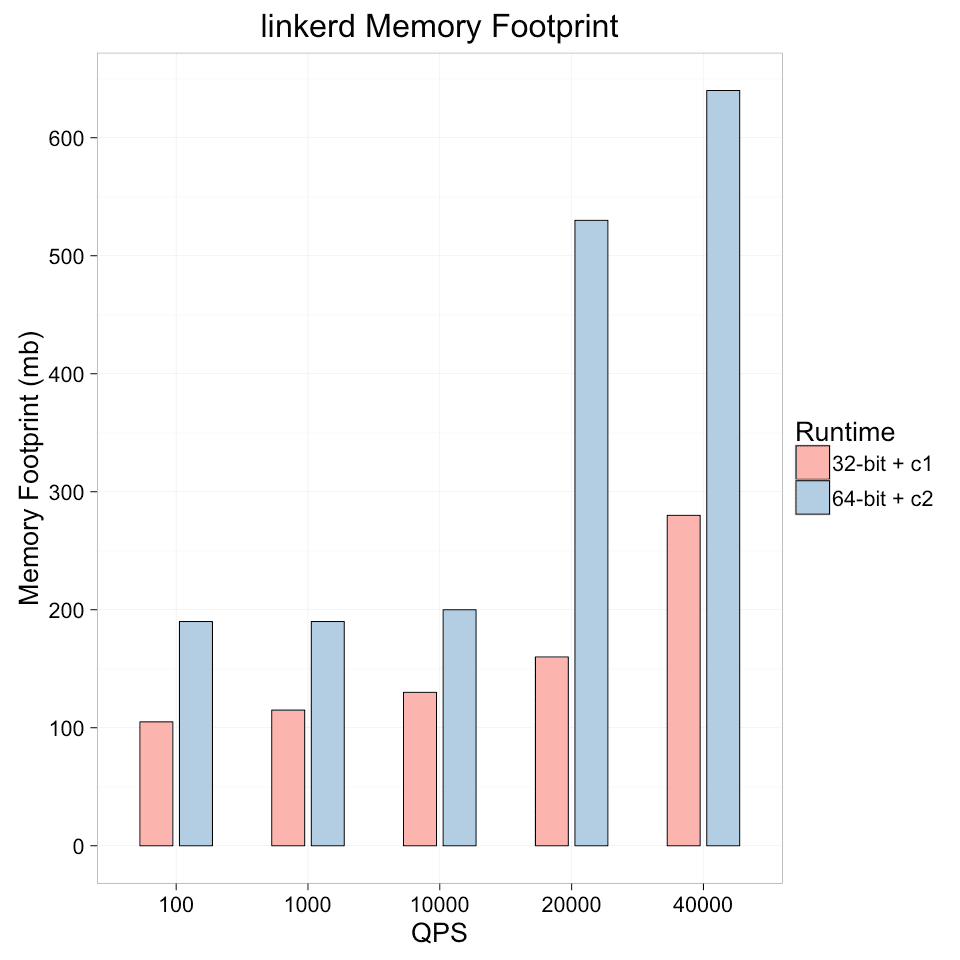
After several weeks of effort, we were able to meet all our goals *except* memory footprint, where we ended 15% above goal. Still, not bad! In short, after this work, the upcoming 0.7.1 release of Linkerd can serve 1,000 HTTP requests per second with a p99 latency of < 1ms and p999 of <5ms, in 115mb of total memory, on commodity cloud VM instances. At a 10th of that volume, 100 rps, it sits at 105mb, just a hair over our goal. And at 40k rps—enough to saturate a 1GB Ethernet card with HTTP proxy traffic—Linkerd requires less than 300mb of memory.
We found two specific techniques to be the most beneficial: turning off one of the two JIT compilers enabled by default (the “C2” compiler), and using a 32-bit, rather than a 64-bit, JVM.
Here’s a chart of Linkerd’s memory footprint at various rps levels, under the old (“64-bit + C2”) and new (“32-bit + C1”) conditions:
Discussion
Of everything that we tried, switching to a 32-bit JVM made the most dramatic difference.
What makes the 64-bit JVM so expensive? One might think it’s due to pointer width, but the JVM has defaulted to compressed pointers for application objects since Java 6u23. The answer, for Linkerd, actually lies in the native libraries loaded by the JVM at startup time. Since these libraries exist outside of the JVM, pointer compression can’t affect them. And since the Linkerd application code itself is actually fairly conservative in terms of memory needed, the cost of loading these 64-bit native libraries as part of the baseline JVM footprint dominates everything else.
Happily, since Linkerd doesn’t actually need to address 2GB of memory under any of the conditions we tested, we effectively lose nothing by moving to the 32-bit JVM. (If anything, we gain memory bandwidth.)
Once we were on the 32-bit JVM, the next biggest impact on memory use was felt by removing the C2 JIT compiler. The JVM’s JIT compilers run as a hierarchy, with the C1 and C2 compilers running different kinds of optimizations. After some experimentation, we found that turning off C2 was helpful in reducing usage by 15-25mb without any substantial effect on latency or CPU.
These two options, when combined, were sufficient to reduce memory footprint by 80% for our target 1k RPS condition.
A Maze of Twisty Passages
In the course of our experiments, we also tried many things that we ended up rejecting—either because they didn’t affect the memory usage, or they made it worse, or they helped but made other aspects of performance worse.
Below is a sampling of some of the more interesting things we tried.
COMPACT PROFILES
The JVM advertises several levels of “compact profiles” designed to reduce the size of the JVM image itself. These are primarily useful for embedded devices that e.g. store the JVM in flash memory. We experimented with these profiles and found no significant impact on runtime memory footprint.
However, when using Linkerd in a Docker container, these options were useful for reducing the size of the container image itself. Of the several levels of compact profiles available, compact3 is the smallest that still provides all the JVM classes required to run Linkerd. We found no performance impact in using compact3 vs a normal 32-bit JVM.
The main drawback to using compact3 is that it doesn’t come with most of the debugging tools one expects from a full JVM, like jstat, jstack, jmap, etc. If you rely on these tools for production debugging, you may want to use the standard 32-bit JDK. (Linkerd itself exports many JVM stats and has a profiler built-in, so you may not be as reliant on JVM tooling as you might expect.)
SHRINKING THE STACK
Linkerd actually doesn’t make heavy use of the stack. In our experiments, shrinking the stack didn’t significantly lower memory usage.
REDUCING THE NUMBER OF JVM INTERNAL THREADS
On an 8-core machine, the JVM will typically start 8 GC threads and 8 JIT compiler threads. You can tune those down using JVM and Linkerd flags. We found that reducing these made latency less predictable, and didn’t significantly improve memory use. We reverted to default settings, allowing the JVM to “tune itself” to run more threads to fit the host’s resources and let the OS scheduler schedule these threads.
TURNING OFF THE JIT ENTIRELY
We tried turning off both JIT compilers and only relying on the bytecode interpreter. This resulted in a substantial reduction on memory footprint, but at the expense of making latency extremely poor and very high variance. We quickly undid these changes.
TURNING OFF THE BYTECODE VERIFIER
Disabling the bytecode verifier reduced CPU utilization by about 15% in our tests.
However, the verifier protects against malicious bytecode and also against bytecode generation bugs. We felt that disabling the verifier could potentially result in a mysteriously unstable production service, so we ultimately decided to keep it on.
A note on high throughput instances
While the new settings allowed Linkerd to scale its own memory consumption without requiring workload-specific tuning, we found that this graceful behavior broke down around 20k rps. Thus, if you’re planning to serve more than 20k HTTP rps from a single Linkerd instance, we currently recommend setting the environment flags JVM_HEAP_MIN and JVM_HEAP_MAX to 256mb for a 32-bit JVM (or 512mb for a 64-bit JVM) to maintain performance.
(In future releases, these parameters may be encoded in a set of QPS-specific options for Linkerd.)
Trying this at home
In order to run Linkerd in your own environment following the recommendations above, generally speaking, we recommend running Linkerd under the 32-bit build of OpenJDK 8.
Of course, running a 32-bit JVM on a 64-bit architecture isn’t quite as simple as just installing it. You have to first install the space-saving 32-bit libraries. Here are a few guides to help you along:
- How to run 32-bit binaries on a 64-bit Debian
- How to run 32-bit binaries on a 64-bit Ubuntu 14.04 LTS
As described in the *Compact Profiles* section above, if you’re running Linkerd in a Docker image, you may also want to consider a compact3 JRE build. Alternatively, we publish Docker images with compact3 set that you can obtain by pulling:
docker pull buoyantio/linkerd:latestFinally, if you want to reproduce the results above, all tests were done by sending sustained load over multiple hours to a pre-release version of Linkerd 0.7.1, using 8-core Debian 8 VMs running on Google Compute Engine. The load tester, proxy, and backends all ran on separate hosts to reduce resource contamination.
Good luck! As always, feel free to reach out to use for help.
Conclusion
In the upcoming 0.7.1 release of Linkerd, memory consumption is dramatically reduced out of the gate—and generally shouldn’t require tuning for workloads under 20k rps. If you’re running Linkerd as a sidecar and doing <= 1k rps per instance, Linkerd should handle sustained load with around 115mb of memory.
Acknowledgements
Thanks for Marius Eriksen and William Morgan for reviewing early drafts of this post. Thanks to Brandon Mitchell of FaunaDB for sharing his knowledge of HotSpot internals with me. Thanks also to David Pollak for suggesting that I try a 32-bit JVM for small heaps many years ago.


